近期,清华材料学院李正操教授课题组,集成电路学院唐建石、吴华强教授课题组与中科院苏州纳米所李清文研究员课题组合作完成的论文《基于后道CNT/IGZO CFET逻辑与模拟型RRAM的单片三维集成混合存算一体架构》(A Hybrid Computing-In-Memory Architecture by Monolithic 3D Integration of BEOL CNT/IGZO-based CFET Logic and Analog RRAM)在2022年微电子器件领域顶级会议——国际电子器件会议(IEEE International Electron Devices Meeting, IEDM)上获得IEEE Brain最佳论文奖 (IEEE Brain Best Paper Award)。

图1 获奖证书
该获奖论文提出了一种基于新型混合内存计算架构的单片三维集成芯片,可显著提高芯片的能效和速度,为人工智能(AI)、高性能计算(HPC)等应用提供了颇有竞争力的技术方案。在图像超分辨率任务演示的性能评估中,该论文提出的芯片架构相对于传统二维芯片具有近50倍的速度优势。
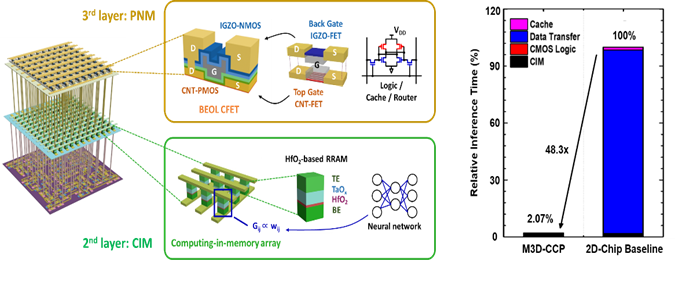
图2 基于单片三维集成的混合存算一体芯片架构。该芯片由3层组成:第一层为标准硅130 nm工艺的CMOS控制逻辑,第二层为基于HfO2 RRAM 1T1R阵列的存算一体层,第三层是基于CNT/IGZO的CFET用于后道逻辑、SRAM缓存和路由。
人工智能的快速发展对芯片的算力与能效提出了越来越高的要求。在过去几年中,基于新型存储器(如阻变存储器RRAM,也称忆阻器)的存算一体技术取得了巨大进展,模拟型RRAM阵列可以基于基尔霍夫定律和欧姆定律以极高的效率执行矩阵-向量乘法(MVM)运算,可大大加速神经网络计算,其能效相比于传统计算硬件可高出几个数量级。
然而,实际神经网络的计算还包含除MVM之外的许多其他操作,如逻辑、缓存、激活函数(如ReLU)和重排等,目前无法在RRAM阵列上有效执行,尽管这些操作可以使用硅CMOS电路实现,但这部分电路会占用很大一部分芯片面积(尤其是用于缓存的SRAM),大大降低基于RRAM的存算一体芯片的整体面积效率。此外,RRAM阵列和缓存之间需要通过总线进行的频繁数据传输,有限的带宽也会导致显著的延迟,限制计算的并行度。
为了解决这一挑战,该论文提出了一种基于单片三维集成的混合存算一体架构,实现了硅CMOS逻辑层、基于RRAM的存算一体层和基于碳纳米管(CNT)/氧化铟镓锌(IGZO)互补场效应晶体管(CFET)的近存计算层的片上垂直堆叠,通过高密度层间通孔(ILV)提供的超高带宽优势,可以高效地实现大规模复杂神经网络运算。此外,该论文利用后道兼容低温工艺首次实现基于CNT/IGZO的后道CFET结构,以此为基础单元实现后道CMOS近存计算功能层,实现神经网络层之间的缓存和逻辑运算。

图3 芯片横截面TEM图像。(a) 本工作展示芯片 (b) RRAM单元和CFET反相器 (c) HfO2基RRAM单元 (d) CFET反相器 (e) CFET共栅薄膜结构。比例尺=250 nm。
材料学院2020级博士生安然和集成电路学院2019级博士生李怡为该论文共同第一作者,集成电路学院唐建石副教授、吴华强教授与材料学院李正操教授为共同通讯作者。该研究获得国家自然科学基金、北京市科技计划、北京市集成电路高精尖创新中心、清华大学-浙江德清材料设计与产业创新联合研究中心等的支持。
IEEE Brain Initiative成立于2015年,旨在创建一个促进跨学科的合作和协调的技术社区,推动研究、标准化以及工程技术的发展,提高我们对于大脑的理解,促进疾病治疗和人类状态改善。